

Notre comparatif des 7 meilleurs site builder en 2022
La conception d’un site Web n’est pas une mince affaire. De nombreux facteurs entrent en jeu dans le processus de conception, et il peut être difficile de savoir par où commencer ou comment s’y prendre.
Heureusement, il existe une variété d’outils disponibles pour les débutants et les experts (selon le niveau auquel vous souhaitez créer votre site). Dans cet article, nous allons classer sept de ces outils en fonction de leur facilité d’utilisation, de leur gamme de modèles, de leur support client et de leur prix. Nous espérons que cette liste vous donnera des indications utiles alors que vous entamez votre voyage de conception de votre propre site !
Quelle est la différence entre les constructeurs de sites Web et les outils de conception de sites ?
Dans le passé, si vous vouliez créer un site Web, vous deviez apprendre le codage ou le design. Toutefois, grâce à l’essor des constructeurs de sites Web, ce n’est plus le cas. Les créateurs de sites Web sont des outils qui vous permettent de créer un site Web sans avoir à apprendre le codage ou la conception. Ils sont généralement faciles à utiliser et sont livrés avec une gamme de modèles que vous pouvez utiliser pour créer un site Web d’aspect professionnel.
Les outils de conception de sites, quant à eux, sont des outils qui vous permettent de créer un site Web en personnalisant son apparence et sa mise en page. Contrairement aux constructeurs de sites Web, les outils de conception de sites exigent que vous ayez quelques connaissances en matière de codage et/ou de conception pour pouvoir les utiliser efficacement.
Pourquoi devriez-vous utiliser un constructeur de site Web ou un outil de conception de site au lieu de coder votre propre site Web à partir de zéro ?
Il y a quelques raisons pour lesquelles vous devriez utiliser un constructeur de site Web ou un outil de conception de site plutôt que de coder votre propre site Web à partir de zéro. Premièrement, les constructeurs de sites Web et les outils de conception sont généralement beaucoup plus faciles à utiliser que le codage, ils constituent donc une excellente option pour les débutants. Deuxièmement, ils offrent une gamme de modèles que vous pouvez utiliser pour créer un site Web d’aspect professionnel en quelques minutes. Troisièmement, la plupart des constructeurs de sites Web et des outils de conception sont accompagnés d’une excellente assistance clientèle, de sorte que vous pouvez obtenir de l’aide si vous rencontrez des problèmes. Enfin, ils sont souvent beaucoup plus abordables que l’embauche d’un développeur Web pour coder votre propre site Web.
Les six meilleurs créateurs de sites pour 2022 en comparaison les uns avec les autres, y compris la facilité d’utilisation, le support client et le prix
Lorsqu’il s’agit de créer un site Web, il existe un grand nombre d’options différentes parmi lesquelles choisir. Cependant, lorsqu’il s’agit des meilleurs constructeurs de sites, il y en a six qui se distinguent des autres. Dans cet article, nous allons comparer ces six constructeurs et les classer en fonction de leur facilité d’utilisation, de leur gamme de modèles, de leur support client et de leur prix.
Avis Webflow (2022) : que vaut vraiment cet outil de création de site ?
Webflow est un outil de création de sites Web qui donne à quiconque le pouvoir de créer et de concevoir des sites Web sans codage. La devise de Webflow est « construire n’importe quoi, n’importe où », et c’est exactement ce que fait ce puissant logiciel.
Par rapport à ses concurrents, Webflow offre des fonctionnalités intéressantes. Par exemple, Webflow vous permet de créer des animations et des interactions personnalisées pour votre site Web sans utiliser de code. Webflow propose également une fonction d’aperçu en direct, qui vous permet de voir votre site Web pendant que vous le construisez. Cette fonction est idéale pour s’assurer que votre site Web ressemble à ce que vous souhaitez.
Webflow permet également de collaborer très facilement avec d’autres concepteurs. Vous pouvez inviter d’autres personnes à travailler sur votre projet avec vous, et vous pouvez également partager des commentaires et des réactions sur votre conception. Un autre avantage de Webflow est qu’il est très facile d’exporter votre site Web une fois que vous avez terminé. Vous pouvez l’exporter sous forme de fichier zip.
Explorez plus en détail ce que vaut réellement Webflow en poursuivant votre lecture sur notre avis complet !
Lisez notre avis sur site123
Site 123 est un constructeur de sites web en ligne qui vous aide à créer un site Web en quelques minutes. Il offre un large éventail de modèles et de designs parmi lesquels choisir, ainsi que des outils de glisser-déposer pour une personnalisation facile. Vous pouvez également ajouter vos propres images, vidéos et autres contenus.
Une chose que nous apprécions à propos de site123, c’est sa facilité d’utilisation. Les outils de glisser-déposer facilitent la personnalisation de votre site Web et vous pouvez choisir parmi de nombreux modèles. De plus, le soutien à la clientèle est excellent – ils offrent un chat en direct, un soutien par courriel et une base de connaissances avec des réponses aux questions courantes.
Cependant, il y a quelques inconvénients. Premièrement, le prix est un peu élevé, surtout si vous voulez utiliser les fonctions avancées. Deuxièmement, le constructeur de sites Web n’est pas aussi polyvalent que certaines des autres options disponibles.
Dans l’ensemble, site123 est un bon créateur de sites Web en ligne qui offre de nombreuses fonctions et modèles parmi lesquels choisir. Si vous cherchez un créateur de sites Web facile à utiliser et doté d’un excellent service à la clientèle, site123 est une bonne option.
Avis Simvoly – Meilleur Créateur de Site 2022 ?
Avec Simvoly il est possible de créer un site Web en un rien de temps. Le constructeur de site est facile à utiliser et vous n’avez pas besoin de compétences en codage. Dans cet examen de Simvoly, nous allons examiner de plus près le constructeur de site et découvrir s’il s’agit vraiment du meilleur constructeur de site Web pour 2022. Le prix de l’abonnement de Simvoly est très raisonnable et vous pouvez utiliser le constructeur de site gratuitement. Les avis des clients sont très positifs et de nombreux utilisateurs recommandent Simvoly. Les entonnoirs sont un excellent moyen d’augmenter votre taux de conversion, et avec Simvoly, il est facile de les créer. Créer un site web ou une boutique en ligne avec Simvoly est vraiment facile. Le constructeur de site est convivial et vous n’avez pas besoin de compétences en codage.
Un funnel de vente ou simplement un entonnoir, est un outil de marketing en ligne qui aide les entreprises à augmenter leurs ventes et leurs prospects. Un entonnoir peut être aussi simple qu’un formulaire d’inscription par courriel sur votre site Web, ou aussi complexe qu’un processus en plusieurs étapes avec plusieurs pages et formulaires.
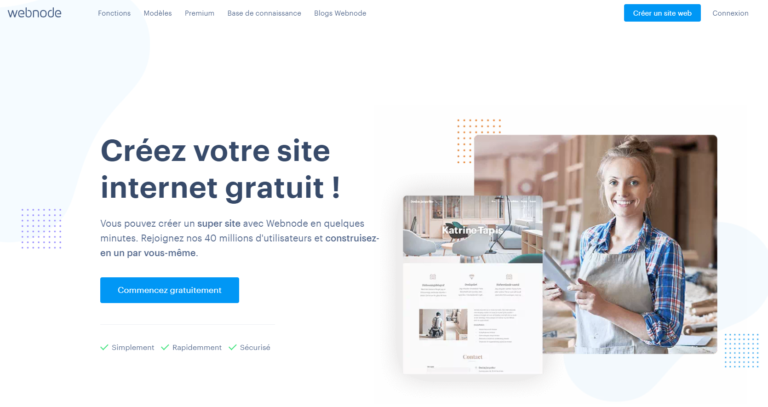
Sitebuilder Webnode : Avis clients, fonctionnalités, tarifs, alternatives
Les fonctionnalités de webnode un constructeur de site facile à utiliser qui vous permet de créer un site Web professionnel en quelques minutes, sans aucune programmation requise. Vous pouvez choisir parmi une variété de modèles et de conceptions, ou créer votre propre conception personnalisée. Webnode offre également un large éventail de fonctionnalités pour faire ressortir votre site Web, y compris le commerce électronique, l’intégration des médias sociaux, et plus encore.
Webnode a une liste impressionnante de clients satisfaits, y compris de nombreuses petites entreprises et organisations. La société est basée en République tchèque et est active depuis 2004.
Le Prix des abonnements: Webnode offre quatre plans de prix différents, selon les caractéristiques et la fonctionnalité que vous avez besoin pour votre site Web. Le plan de base est libre et inclut 5GB de stockage, 1GB de largeur de bande, et un nombre limité de fonctionnalités. Les plans payants commencent à 4,99 $/mois et comprennent un stockage et une bande passante illimités, ainsi qu’un plus grand nombre de fonctionnalités.
Avis Strikingly (2022) : ce créateur de site vaut-il le détour ?
Strikingly est le sitebuilder le plus simple d’utilisation de loin. Le site est facile à naviguer et mon site est superbe sur n’importe quel appareil.
J’ai eu quelques difficultés à importer mon ancien site, mais le service clientèle a été très utile pour résoudre le problème. Dans l’ensemble, je suis très satisfait de Strikingly !
Strikingly est un excellent constructeur de site pour les personnes qui veulent créer un site Web professionnel sans apprendre à coder. Le site est facile à utiliser et mon site est superbe sur n’importe quel appareil. Le service clientèle est utile et réactif, et je recommande vivement Strikingly à quiconque cherche à créer un site Web.
J’adore absolument Strikingly ! Le constructeur de site est si facile à utiliser et mon site est superbe sur n’importe quel appareil. Le service clientèle est incroyable et toujours disponible pour aider en cas de questions ou de problèmes.
L’équipe du service clientèle est très utile et a répondu rapidement à mes questions. Dans l’ensemble, je suis très satisfait de Strikingly !
Avis Wifeo : une bonne solution pour la création de sites ?
Wifeo est un sitebuilder français et plateforme de création de sites web. Elle a été créée en 2007 par Alexandre Rimbaud et Damien Viel. L’entreprise est basée à Bordeaux, en France
Wifeo propose un constructeur de sites Web qui permet aux utilisateurs de créer un site Web sans aucune connaissance en codage. La plateforme est facile à utiliser et offre un large éventail de modèles et de fonctionnalités
Le prix de Wifeo commence à 9 $ par mois pour le plan de base, qui comprend 1 Go de stockage, 5 Go de bande passante et un nom de domaine gratuit. Le plan Pro coûte 19 $ par mois et comprend 10 Go de stockage, 10 Go de bande passante et un nom de domaine gratuit.
Wifeo connaît une croissance constante depuis son lancement en 2007. L’entreprise affirme avoir plus de 1,5 million d’utilisateurs dans le monde entier.
Voog avis Tarif & Fonctionnalités
Voog a beaucoup de fonctionnalité pour la création de sites, mais comment se compare-t-il aux autres constructeurs de sites en termes de prix ?La création d’un site peut être une décision importante, il est donc crucial de comparer toutes les solutions qui sont proposés.
La création et l’hébergement de sites peuvent être coûteux, il est donc important de faire des recherches avant de choisir un constructeur de site. Voog propose des tarifs d’abonnement compétitifs, à partir de seulement 5 $/mois. Vous pouvez également choisir de payer annuellement plutôt que mensuellement, ce qui vous permet d’économiser 10 %.
Voog propose également un essai gratuit afin que vous puissiez tester les fonctionnalités avant de vous engager dans un abonnement. Et si vous décidez d’annuler votre abonnement, Voog vous remboursera toujours intégralement – sans poser de questions. Alors pourquoi ne pas essayer Voog dès aujourd’hui ?
Le choix de nos experts sur le meilleur site builder Rapport/Qualité/Prix:
Les sites Web sont de plus en plus populaires, car de plus en plus de personnes s’efforcent de créer des sites Web d’aspect professionnel sans avoir à apprendre le codage ou la conception. Dans cet article, nous allons classer les six meilleurs créateurs de sites Web pour 2022 en nous basant sur divers facteurs, tels que la facilité d’utilisation, la gamme de modèles, le support client et le prix.
Le choix de nos experts pour le meilleur rapport qualité-prix des constructeurs de sites est Site123. Il est facile à utiliser, avec une large gamme de modèles à choisir, et un excellent support client. De plus, c’est l’un des constructeurs de sites les moins chers du marché.
Simvoly est également un excellent choix pour les petites entreprises, car il offre un large éventail de fonctionnalités, comme la possibilité de créer des magasins et d’accepter des paiements.
Si vous recherchez un constructeur de site qui offre plus de flexibilité et de personnalisation, Webnode pourrait être une meilleure option pour vous. Il est un peu plus cher que Simvoly, mais il est livré avec une foule de fonctionnalités qui vous permettent de créer un site Web vraiment unique.
Si vous disposez d’un budget serré, Wifeo pourrait être le constructeur de site Web idéal pour vous. C’est l’une des options les moins chères disponibles, et il est livré avec un large éventail de modèles à choisir.
Conclusion
J’espère que cet article vous a été utile. Il est important de garder à l’esprit que les constructeurs de sites Web sont de plus en plus populaires, car les gens s’efforcent de créer des sites Web d’apparence professionnelle sans avoir à apprendre le codage ou la conception. Dans cet article, nous avons classé les six meilleurs créateurs de sites Web pour 2022 en fonction de divers facteurs, tels que la facilité d’utilisation, la gamme de modèles, le support client et le prix. Donc, si vous êtes à la recherche d’un excellent constructeur de site Web qui vous permettra de créer un site Web magnifique et fonctionnel, assurez-vous de consulter l’un des six constructeurs que nous avons présentés dans cet article !
FAQ
Un constructeur de sites Web est une plateforme qui permet aux utilisateurs de créer leurs propres sites Web sans avoir à apprendre le codage ou la conception. Les constructeurs de sites Web sont de plus en plus populaires, car les gens s’efforcent de créer des sites Web d’aspect professionnel sans avoir à passer des heures à apprendre à coder.
L’utilisation d’un constructeur de site Web présente de nombreux avantages, notamment
- La facilité d’utilisation : La plupart des créateurs de sites Web sont très faciles à utiliser, même pour ceux qui ne sont pas férus de technologie
- Gamme de modèles : La plupart des créateurs de sites Web offrent un large éventail de modèles parmi lesquels choisir, afin que vous puissiez trouver celui qui correspond à votre style et à vos besoins
- Assistance à la clientèle : Si vous avez des questions ou des problèmes avec votre site Web, la plupart des constructeurs offrent un excellent support client qui peut vous aider à résoudre le problème
- Le prix : Les constructeurs de sites Web offrent généralement une gamme d’options de prix, afin que vous puissiez trouver celui qui convient à votre budget
Lorsque vous créez un site Web à l’aide d’un constructeur de sites Web, il y a quelques points à garder à l’esprit afin d’éviter tout problème. Tout d’abord, veillez à choisir un modèle qui correspond à vos besoins. Il existe une grande variété de modèles parmi lesquels choisir, vous devriez donc pouvoir en trouver un qui correspond à votre style et à votre activité.
En outre, veillez à lire les conditions générales du constructeur de sites Web avant de vous inscrire. Cela vous permettra d’éviter toute surprise en cours de route. Enfin, si vous avez des questions ou des problèmes avec votre site Web, veillez à contacter le service clientèle. Ils seront en mesure de vous aider à résoudre tout problème.



 par
par